
useEffect 完全指南
March 9, 2019
你已经用 Hooks 写了几个组件,甚至做了个小应用。你对 API 很满意,过程中还学到了一些技巧。你甚至写了几个 自定义 Hook 来抽离重复逻辑(一下子少了 300 行代码!),还向同事们展示了一番。“干得漂亮”,他们说。
但有时候用 useEffect 时,总觉得哪里不太对劲。你隐约觉得自己遗漏了什么。它看起来和类组件的生命周期很像……可真的是这样吗?你会开始问自己这样的问题:
- 🤔 如何用
useEffect实现componentDidMount的效果? - 🤔 如何在
useEffect里正确地获取数据?[]又代表什么? - 🤔 我需要把函数作为 effect 的依赖项吗?
- 🤔 为什么有时候会出现无限重复获取数据的死循环?
- 🤔 为什么有时候 effect 里拿到的是旧的 state 或 prop?
刚开始用 Hooks 的时候,我也被这些问题困扰。甚至在写最初的文档时,我对其中一些细节也没完全搞明白。后来我经历了几次“啊哈”时刻,现在想和你分享。这篇深度解析会让你对这些问题的答案一目了然。
要看懂这些答案,我们需要退一步思考。这篇文章的目标不是给你一堆速查表,而是让你真正“理解”useEffect。其实没什么新东西要学,反而我们大部分时间是在去除旧有认知。
直到我不再用熟悉的类生命周期方法去看待 useEffect,一切才豁然开朗。
“放下你所学的一切。” —— 尤达

本文假设你已经对 useEffect API 有一定了解。
而且它真的很长,像本小册子。这是我喜欢的写作方式。但如果你赶时间或者兴趣不大,下面有 TLDR 总结。
如果你不喜欢深度解析,可以等这些解释在别处出现。就像 React 2013 年刚出来时一样,大家需要时间去接受和传授新的思维模型。
TLDR
如果你不想看完整篇文章,这里有个快速 TLDR 总结。如果有些地方不明白,可以往下翻找到相关内容。
如果你打算阅读全文,可以跳过这里,文末我会再贴一次链接。
🤔 问题:如何用 useEffect 实现 componentDidMount?
虽然你可以用 useEffect(fn, []),但这并不是完全等价。与 componentDidMount 不同,它会捕获当时的 props 和 state。所以即使在回调里,你看到的也是初始的 props 和 state。如果你想获取“最新”的某个值,可以写到 ref 里。但通常有更简单的代码结构,不必这样做。记住,effect 的思维模型和生命周期方法不同,强行找一一对应反而会让你更困惑。要高效使用,你需要“用 effect 的方式思考”,它们的模型更像是实现同步,而不是响应生命周期事件。
🤔 问题:如何在 useEffect 里正确获取数据?[] 是什么?
这篇文章 是用 useEffect 获取数据的好入门,建议读完!没这篇长。[] 表示 effect 没有用到任何参与 React 数据流的值,因此只会执行一次是安全的。但如果实际上用到了某个值,这就容易出 bug。你需要学会一些策略(主要是 useReducer 和 useCallback),它们可以消除依赖,而不是错误地省略依赖。
🤔 问题:effect 的依赖里要不要写函数?
建议把不需要用到 props 或 state 的函数提升到组件外部,把只在 effect 里用的函数写到 effect 里。如果 effect 里还是用到了渲染作用域的函数(包括 props 传进来的),就在定义处用 useCallback 包裹,然后重复这个过程。为什么要这样?因为函数能“看到” props 和 state 的值——它们参与数据流。FAQ 里有更详细的解释。
🤔 问题:为什么有时候会出现无限重复获取数据的死循环?
如果你在 effect 里获取数据但没写第二个依赖参数,就会这样。没有依赖参数时,effect 每次渲染后都会执行——而设置 state 又会再次触发 effect。或者你依赖了一个每次都会变的新值,也会死循环。可以一个个去掉依赖找出是谁,但随意删依赖或乱写 [] 通常不是好办法。应该从根源上解决问题,比如函数导致的,可以把它们写到 effect 里、提升出去或用 useCallback。要避免对象频繁创建,可以用 useMemo。
🤔 问题:为什么 effect 里有时候拿到的是旧的 state 或 prop?
effect 总是“看到”它定义时那次渲染的 props 和 state。这样有助于防止 bug,但有时也会让人不爽。这种情况可以用可变 ref 显式维护某个值(文末有讲)。如果你发现 effect 里拿到的是旧的 props 或 state,而你觉得不该这样,可能是漏写了依赖。试试这个 lint 规则来训练自己发现这些问题。几天后你就会习惯了。FAQ 里也有相关解答。
希望这个 TLDR 对你有帮助!否则我们就正式开始吧。
每次渲染都有自己的 Props 和 State
在聊 effect 之前,我们先聊聊渲染。
来看一个计数器,注意高亮那一行:
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}这意味着什么?count 会“监听” state 的变化并自动更新吗?刚学 React 时你可能会这么想,但这不是准确的思维模型。
在这个例子里,count 只是个普通数字。 它不是神奇的“数据绑定”、不是“监听器”、不是“代理”,什么都不是。它就是个普通数字,比如:
const count = 42;
// ...
<p>You clicked {count} times</p>
// ...组件第一次渲染时,useState() 返回的 count 是 0。当我们调用 setCount(1) 时,React 会再次调用我们的组件,这次 count 就是 1。以此类推:
// 第一次渲染
function Counter() {
const count = 0; // useState() 返回
// ...
<p>You clicked {count} times</p>
// ...
}
// 点击后,组件再次被调用
function Counter() {
const count = 1; // useState() 返回
// ...
<p>You clicked {count} times</p>
// ...
}
// 再点一次,组件再次被调用
function Counter() {
const count = 2; // useState() 返回
// ...
<p>You clicked {count} times</p>
// ...
}每当我们更新 state,React 就会调用组件。每次渲染结果“看到”的都是属于自己的 counter 状态值,这个值在函数内部是常量。
所以这行代码并没有什么特殊的数据绑定:
<p>You clicked {count} times</p>它只是把一个数字值嵌进渲染输出。 这个数字由 React 提供。当我们 setCount 时,React 会用新的 count 值再次调用组件,然后更新 DOM 以匹配最新的渲染输出。
关键点在于,任何一次渲染里的 count 常量都不会随时间改变。是我们的组件被再次调用——每次渲染“看到”的都是属于那次渲染的 count 值,彼此隔离。
(想深入了解这个过程,可以看我的文章 React as a UI Runtime)
每次渲染都有自己的事件处理函数
到目前为止都还好。那么事件处理函数呢?
看这个例子。它会在三秒后弹出当前 count:
function Counter() {
const [count, setCount] = useState(0);
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
<button onClick={handleAlertClick}>
Show alert
</button>
</div>
);
}假设我按如下顺序操作:
- 递增计数器到 3
- 点击“Show alert”
- 在定时器触发前再递增到 5
你觉得弹窗会显示多少?会是 5(弹窗时的最新值),还是 3(点击时的值)?
以下有剧透
如果你觉得这个行为不太合理,可以想象一个更实际的例子:一个聊天应用,state 里有当前收信人 ID,点击 Send 按钮。这篇文章有详细解释,正确答案是 3。
弹窗会“捕获”你点击按钮时的 state。
(当然也可以实现另一种行为,但这里我们只关注默认情况。建立思维模型时,区分“最常见路径”和特殊用法很重要。)
那它是怎么做到的?
我们说过,count 在每次组件调用时都是常量。需要强调的是——我们的函数会被多次调用(每次渲染一次),但每次调用里的 count 值都是常量,等于那次渲染的 state。
其实这不是 React 独有——普通函数也一样:
function sayHi(person) {
const name = person.name;
setTimeout(() => {
alert('Hello, ' + name);
}, 3000);
}
let someone = {name: 'Dan'};
sayHi(someone);
someone = {name: 'Yuzhi'};
sayHi(someone);
someone = {name: 'Dominic'};
sayHi(someone);在这个例子里,外部的 someone 变量被多次赋值。(就像 React 里组件的当前 state 会变。)但在 sayHi 里,有个本地的 name 常量,和每次调用的 person 绑定。 这个常量是局部的,所以每次调用互不影响!结果就是,定时器触发时,每个弹窗都“记得”自己的 name。
这就解释了事件处理函数为什么会捕获点击时的 count。如果我们用同样的替换原则,每次渲染“看到”的都是自己的 count:
// 第一次渲染
function Counter() {
const count = 0; // useState() 返回
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
// ...
}
// 点击后,组件再次被调用
function Counter() {
const count = 1; // useState() 返回
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
// ...
}
// 再点一次,组件再次被调用
function Counter() {
const count = 2; // useState() 返回
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
// ...
}所以每次渲染都会返回自己的 handleAlertClick“版本”。每个版本都“记得”自己的 count:
// 第一次渲染
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + 0);
}, 3000);
}
// ...
<button onClick={handleAlertClick} /> // 里面是 0
// ...
}
// 点击后,组件再次被调用
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + 1);
}, 3000);
}
// ...
<button onClick={handleAlertClick} /> // 里面是 1
// ...
}
// 再点一次,组件再次被调用
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + 2);
}, 3000);
}
// ...
<button onClick={handleAlertClick} /> // 里面是 2
// ...
}这就是为什么这个 demo里,事件处理函数“属于”某次渲染,点击时用的就是那次渲染的 counter state。
在任何一次渲染里,props 和 state 永远不会变。 既然 props 和 state 在不同渲染间是隔离的,依赖它们的值(包括事件处理函数)也是。它们也“属于”某次渲染。所以即使事件处理函数里的异步函数,也会“看到”同一个 count。
补充说明:上面我把具体的 count 值直接写进了 handleAlertClick,这种替换是安全的,因为 count 在某次渲染里不会变,是 const,是数字。对对象等其它值也可以这样想,只要我们不去修改 state。用新对象调用 setSomething(newObj) 而不是修改原对象是安全的,因为之前渲染的 state 不会变。
每次渲染都有自己的 Effect
本来这篇是讲 effect 的,但我们还没正式聊 effect!现在来补上。其实 effect 和前面说的没什么不同。
回到文档里的例子:
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `You clicked ${count} times`;
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}问题来了:effect 是怎么读取到最新的 count 状态的?
也许你觉得有某种“数据绑定”或“监听”机制,让 effect 里的 count 实时更新?或者 count 是个可变变量,React 会在组件里设置它,这样 effect 总能拿到最新值?
并不是。
我们已经知道,count 在某次组件渲染里是常量。事件处理函数“看到”的是它所属渲染的 count,因为 count 在它作用域里。effect 也是一样!
不是 effect 里的 count 变量会变,而是effect 函数本身每次渲染都不一样。
每个版本“看到”的都是它所属渲染的 count:
// 第一次渲染
function Counter() {
// ...
useEffect(
// 第一次渲染的 effect
() => {
document.title = `You clicked ${0} times`;
}
);
// ...
}
// 点击后,组件再次被调用
function Counter() {
// ...
useEffect(
// 第二次渲染的 effect
() => {
document.title = `You clicked ${1} times`;
}
);
// ...
}
// 再点一次,组件再次被调用
function Counter() {
// ...
useEffect(
// 第三次渲染的 effect
() => {
document.title = `You clicked ${2} times`;
}
);
// ..
}React 会记住你提供的 effect 函数,在 DOM 更新并让浏览器完成绘制后再运行它。
所以即使我们说这是一个“概念上的 effect”(更新文档标题),其实每次渲染都是不同的函数——每个 effect 函数“看到”的都是它所属渲染的 props 和 state。
可以把 effect 想象成渲染结果的一部分。
严格来说并不是(这样才能支持 Hook 组合),但在我们构建的思维模型里,effect 函数和事件处理函数一样,属于某次渲染。
确保理解后,我们来回顾下第一次渲染:
- React: 给我 state 为
0时的 UI。 - 你的组件:
- 渲染结果是:
<p>You clicked 0 times</p>。 - 还要记得渲染后运行这个 effect:
() => { document.title = 'You clicked 0 times' }。
- 渲染结果是:
- React: 好的,更新 UI。浏览器,我要往 DOM 里加点东西。
- 浏览器: 好,已经渲染到屏幕上了。
- React: 现在我要运行你给我的 effect。
- 运行
() => { document.title = 'You clicked 0 times' }。
- 运行
再来看点击后的流程:
- 你的组件: React,把我的 state 设为
1。 - React: 给我 state 为
1时的 UI。 - 你的组件:
- 渲染结果是:
<p>You clicked 1 times</p>。 - 还要记得渲染后运行这个 effect:
() => { document.title = 'You clicked 1 times' }。
- 渲染结果是:
- React: 好的,更新 UI。浏览器,我改了 DOM。
- 浏览器: 好,已经渲染到屏幕上了。
- React: 现在我要运行刚刚渲染对应的 effect。
- 运行
() => { document.title = 'You clicked 1 times' }。
- 运行
每次渲染都有自己的……一切
现在我们知道,effect 在每次渲染后都会运行,概念上属于组件输出的一部分,并且“看到”的是那次渲染的 props 和 state。
做个思想实验。看这段代码:
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
setTimeout(() => {
console.log(`You clicked ${count} times`);
}, 3000);
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}如果我连续点击几次,间隔很短,日志会是什么样?
以下有剧透
你可能以为这是个坑,结果很反直觉。其实不是!我们会看到一串日志——每条都属于某次渲染,各自有自己的 count。你可以自己试试:
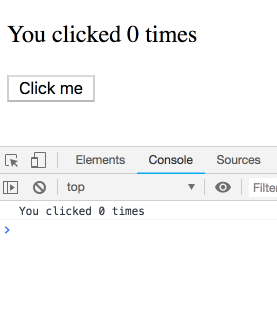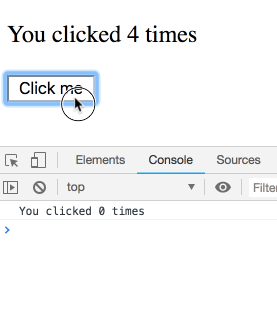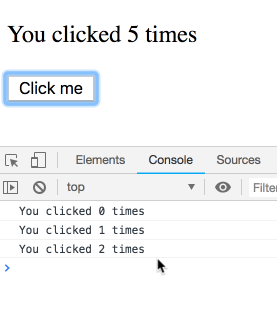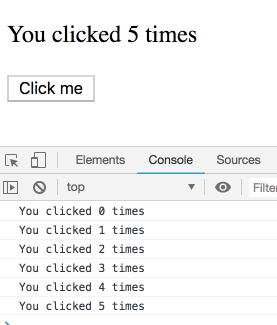
你可能会说:“当然是这样!还能怎么回事?”
但类组件的 this.state 可不是这样。很容易以为这个类实现是等价的:
componentDidUpdate() {
setTimeout(() => {
console.log(`You clicked ${this.state.count} times`);
}, 3000);
}但 this.state.count 总是指向最新的 count,而不是某次渲染的。你会看到每次都打印 5:
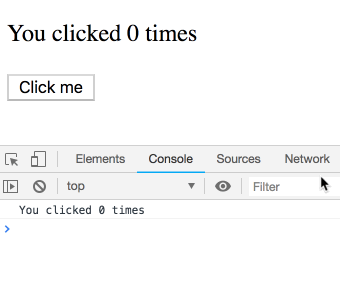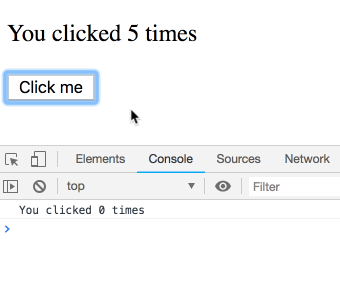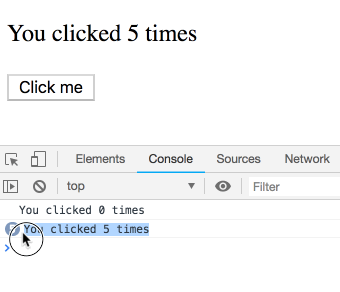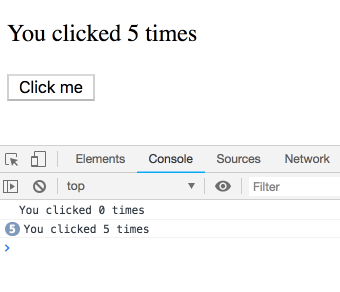
有趣的是,Hooks 这么依赖 JS 闭包,结果反而是类实现更容易出现闭包里值不对的经典坑。其实问题根源是“可变性”(React 在类里会修改 this.state 指向最新 state),而不是闭包本身。
闭包在你捕获的值不会变时非常好用。这样思考很简单,因为你引用的本质上是常量。 正如我们说的,props 和 state 在某次渲染里不会变。顺便说一句,我们也可以用闭包修复类版。
逆流而上
现在要明确一点:组件渲染里的每个函数(包括事件处理、effect、定时器或 API 调用)都捕获了定义它时那次渲染的 props 和 state。
所以这两个例子是等价的:
function Example(props) {
useEffect(() => {
setTimeout(() => {
console.log(props.counter);
}, 1000);
});
// ...
}function Example(props) {
const counter = props.counter;
useEffect(() => {
setTimeout(() => {
console.log(counter);
}, 1000);
});
// ...
}无论你是在组件里“早”读取 props 或 state,都不会变! 在一次渲染作用域里,props 和 state 是不变的。(解构 props 更能体现这一点。)
当然,有时候你确实想在某个回调里获取“最新”值。最简单的办法是用 ref,详见这篇文章最后一节。
注意,如果你想在过去某次渲染里的函数里读取未来的 props 或 state,你就是在逆流而上。这不是错(有时必须这样),但会让代码不那么“干净”。这是有意为之,因为这样能突出哪些代码依赖时序、容易出错。类组件里这种情况不明显。
这里有个计数器例子,模拟类组件行为:
function Example() {
const [count, setCount] = useState(0);
const latestCount = useRef(count);
useEffect(() => {
// 设置最新值
latestCount.current = count;
setTimeout(() => {
// 读取最新值
console.log(`You clicked ${latestCount.current} times`);
}, 3000);
});
// ...
你可能觉得在 React 里修改东西有点怪。但其实 React 在类里也是这样重新赋值 this.state 的。和捕获的 props、state 不同,你无法保证任何回调里读取 latestCount.current 得到的值是确定的,因为它随时可变。这也是为什么这不是默认行为,你得主动 opt-in。
那清理(cleanup)是怎么回事?
如文档所说,有些 effect 需要清理阶段,比如取消订阅。
看这段代码:
useEffect(() => {
ChatAPI.subscribeToFriendStatus(props.id, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(props.id, handleStatusChange);
};
});假设第一次渲染时 props 是 {id: 10},第二次是 {id: 20}。你可能会以为流程是:
- React 清理
{id: 10}的 effect。 - React 渲染
{id: 20}的 UI。 - React 运行
{id: 20}的 effect。
(其实不是这样。)
按这种思维模型,你可能觉得 cleanup “看到”的是旧 props,因为它在重新渲染前运行,而新 effect “看到”的是新 props,因为它在渲染后运行。这是直接从类生命周期借来的思维模型,但这里并不准确。我们来看看为什么。
React 只有在让浏览器完成绘制后才运行 effect。这让你的应用更快,因为大部分 effect 不需要阻塞屏幕更新。effect 的清理也是延迟的。上一个 effect 的清理是在新 props 渲染后才执行的:
- React 渲染
{id: 20}的 UI。 - 浏览器绘制。我们看到
{id: 20}的 UI。 - React 清理
{id: 10}的 effect。 - React 运行
{id: 20}的 effect。
你可能会问:既然清理是在 props 变成 {id: 20} 后才执行,为什么还能“看到”旧的 {id: 10}?
我们前面已经说过…… 🤔

引用前文:
组件渲染里的每个函数(包括事件处理、effect、定时器或 API 调用)都捕获了定义它时那次渲染的 props 和 state。
现在答案很清楚了!effect 的清理不会读取“最新”的 props。它读取的,是定义它那次渲染的 props:
// 第一次渲染,props 是 {id: 10}
function Example() {
// ...
useEffect(
// 第一次渲染的 effect
() => {
ChatAPI.subscribeToFriendStatus(10, handleStatusChange);
// 第一次渲染的 cleanup
return () => {
ChatAPI.unsubscribeFromFriendStatus(10, handleStatusChange);
};
}
);
// ...
}
// 下一次渲染,props 是 {id: 20}
function Example() {
// ...
useEffect(
// 第二次渲染的 effect
() => {
ChatAPI.subscribeToFriendStatus(20, handleStatusChange);
// 第二次渲染的 cleanup
return () => {
ChatAPI.unsubscribeFromFriendStatus(20, handleStatusChange);
};
}
);
// ...
}王朝兴衰、太阳变白矮星、最后的文明终结,也无法让第一次渲染 effect 的 cleanup 看到的 props 变成 {id: 10} 以外的值。
正因为如此,React 才能在绘制后处理 effect,让你的应用默认更快。旧的 props 依然保留着,供代码需要时使用。
同步,而非生命周期
我最喜欢 React 的一点,就是它把初始渲染和更新统一起来了。这降低了程序的复杂度。
比如我的组件是这样的:
function Greeting({ name }) {
return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}无论我先渲染 <Greeting name="Dan" /> 再渲染 <Greeting name="Yuzhi" />,还是直接渲染 <Greeting name="Yuzhi" />,最终看到的都是 “Hello, Yuzhi”。
人们常说:“重要的是过程,不是结果”。但在 React 里,正好相反。重要的是结果,不是过程。 这就是 jQuery 里 $.addClass 和 $.removeClass(“过程”)与 React 里直接指定 CSS class(“结果”)的区别。
React 会根据当前 props 和 state 同步 DOM。 渲染时没有“挂载”或“更新”的区别。
effect 也应该这样思考。useEffect 让你能根据 props 和 state 同步 React 树外的东西。
function Greeting({ name }) {
useEffect(() => {
document.title = 'Hello, ' + name;
});
return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}这和熟悉的挂载/更新/卸载模型有细微区别。一定要真正理解这一点。如果你试图让 effect 根据组件是不是第一次渲染而表现不同,你就是在逆流而上! 如果结果依赖“过程”而不是“结果”,那就没同步好。
无论我们是先渲染了 props A、B、C,还是直接渲染了 C,最终结果都应该一样。虽然中间可能有临时差异(比如数据还在加载),但最终结果应该一致。
当然,每次渲染都运行所有 effect 可能效率不高。(有时还会导致死循环。)
那该怎么优化呢?
教 React 对比你的 Effect
我们已经在 DOM 上学过这个教训了。React 不会每次都操作整个 DOM,只会更新真正变了的部分。
比如你把
<h1 className="Greeting">
Hello, Dan
</h1>更新为
<h1 className="Greeting">
Hello, Yuzhi
</h1>React 会看到两个对象:
const oldProps = {className: 'Greeting', children: 'Hello, Dan'};
const newProps = {className: 'Greeting', children: 'Hello, Yuzhi'};它会检查每个 prop,发现只有 children 变了,于是只更新 DOM:
domNode.innerText = 'Hello, Yuzhi';
// domNode.className 不用动effect 能不能也这样?如果没必要就别重新运行 effect。
比如组件因为 state 变化而重新渲染:
function Greeting({ name }) {
const [counter, setCounter] = useState(0);
useEffect(() => {
document.title = 'Hello, ' + name;
});
return (
<h1 className="Greeting">
Hello, {name}
<button onClick={() => setCounter(count + 1)}>
Increment
</button>
</h1>
);
}但我们的 effect 并没有用到 counter。effect 只负责同步 document.title 和 name,而 name 没变。 每次 counter 变都重新赋值 document.title,其实没必要。
那 React 能不能……对比 effect?
let oldEffect = () => { document.title = 'Hello, Dan'; };
let newEffect = () => { document.title = 'Hello, Dan'; };
// React 能看出这俩函数做的是一样的吗?不行。React 不知道函数里做了什么,除非运行它。(而且源码里也没有具体值,只是闭包了 name。)
所以如果你想避免不必要的 effect 运行,可以给 useEffect 传一个依赖数组(也叫“deps”):
useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]); // 依赖就像你告诉 React:“嘿,我知道你看不懂这个函数,但我保证它只用到了 name,没用别的。”
如果这些值和上次一样,React 就可以跳过 effect:
const oldEffect = () => { document.title = 'Hello, Dan'; };
const oldDeps = ['Dan'];
const newEffect = () => { document.title = 'Hello, Dan'; };
const newDeps = ['Dan'];
// React 不看函数内容,但可以对比 deps。
// 全都一样,就不用运行新的 effect。只要依赖数组里有一个值变了,就必须运行 effect。同步一切!
不要对依赖撒谎
对 React 撒谎依赖会有坏结果。直觉上你也能理解,但我见过几乎所有用类思维用 useEffect 的人都试图“作弊”。(我一开始也这样!)
function SearchResults() {
async function fetchData() {
// ...
}
useEffect(() => {
fetchData();
}, []); // 这样可以吗?其实不总行——而且有更好的写法。
// ...
}(Hooks FAQ 解释了该怎么做。我们后面会回到这个例子。)
“但我只想让它挂载时运行一次!”你可能会说。记住:如果你写了依赖,所有 effect 里用到的组件内的值都必须写进去。包括 props、state、函数——只要是组件里的。
有时候这么做会出问题。比如你可能遇到无限循环获取数据,或者 socket 被频繁重建。解决办法不是删依赖。 我们马上会讲怎么解决。
但在此之前,先搞清楚问题。
依赖撒谎会怎样
如果依赖数组包含了 effect 用到的所有值,React 就知道何时重新运行它:
useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]);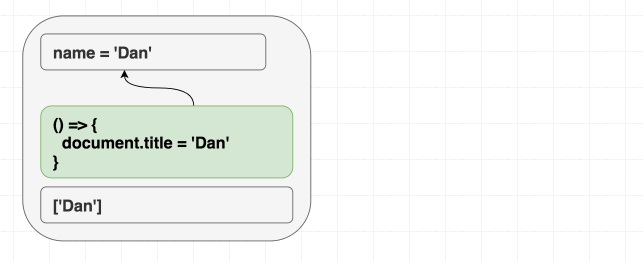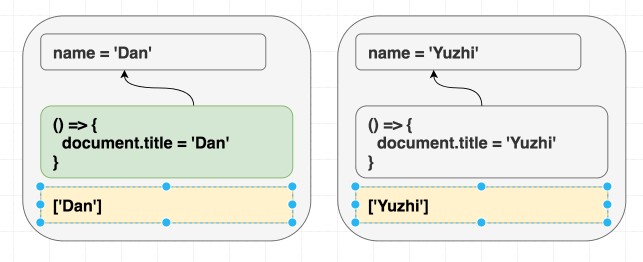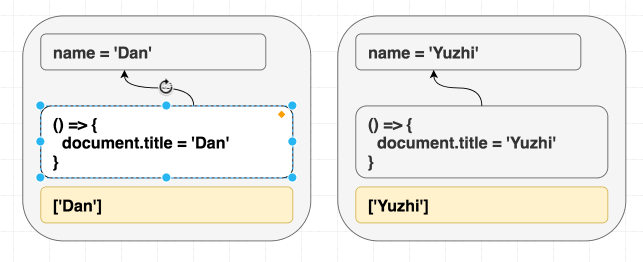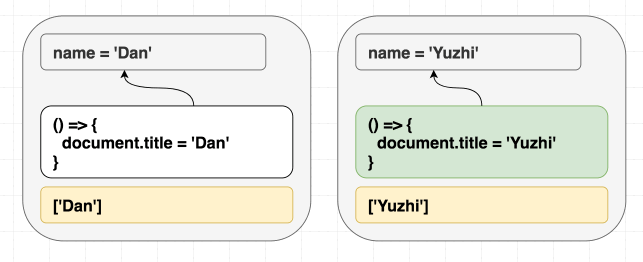
(依赖变了,重新运行 effect。)
但如果我们给它写了 [],effect 就不会重新运行:
useEffect(() => {
document.title = 'Hello, ' + name;
}, []); // 错误:name 没写进依赖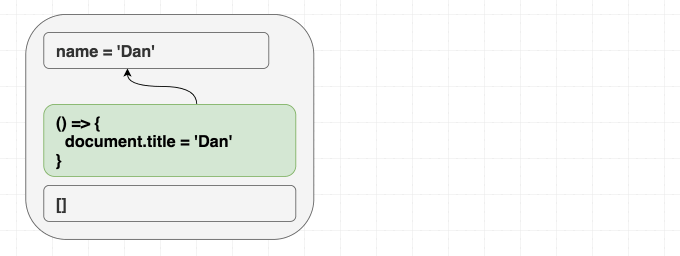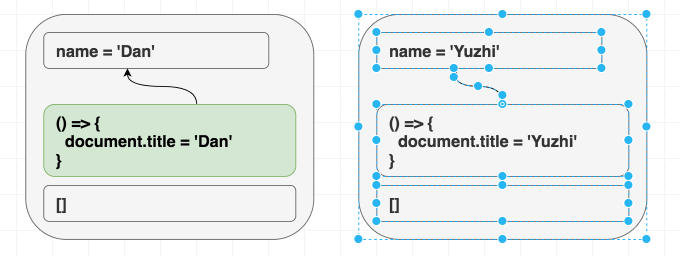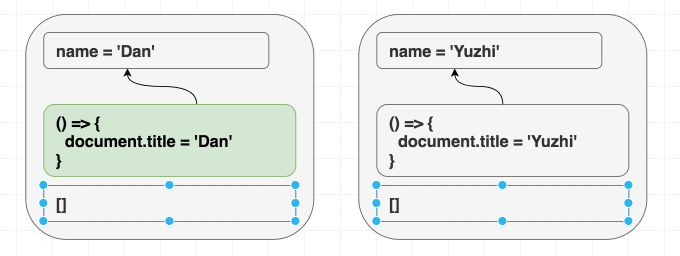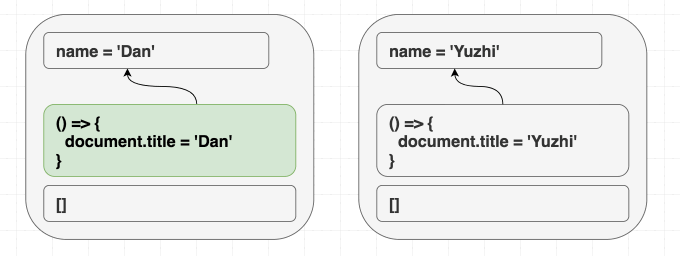
(依赖一样,跳过 effect。)
这个例子问题很明显。但在类组件思维下,直觉会骗你。
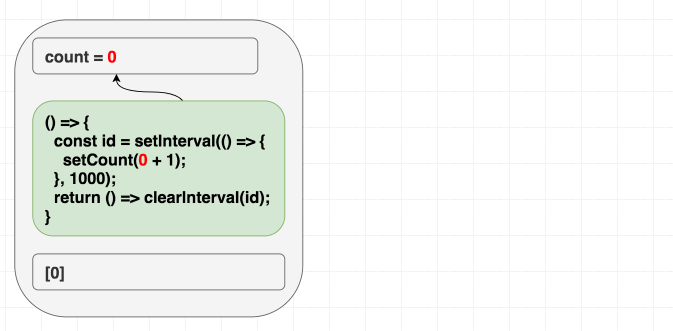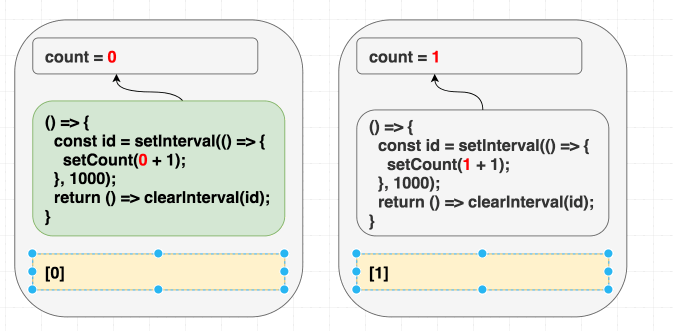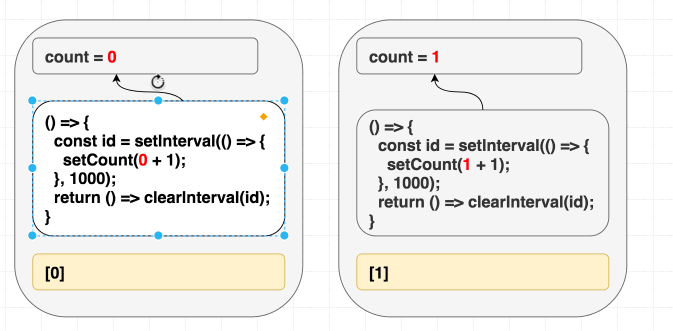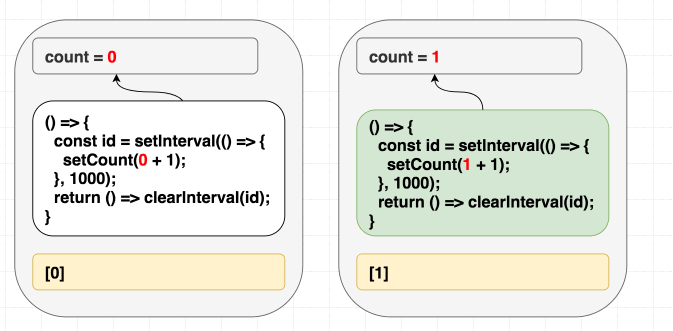
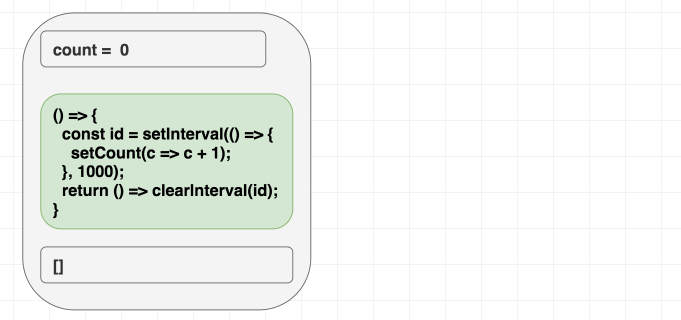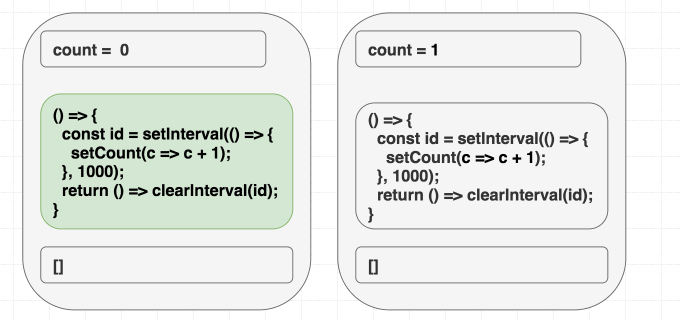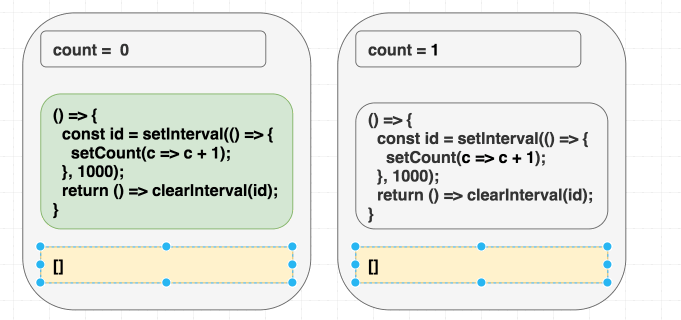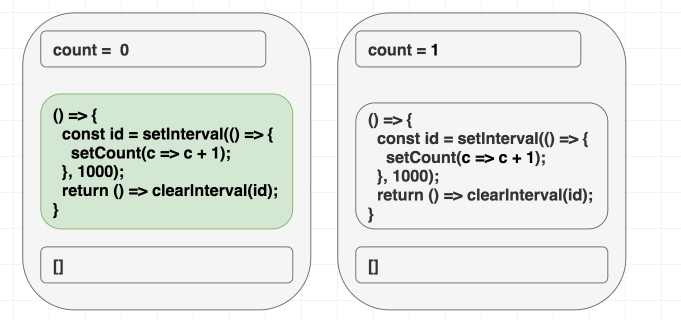
比如我们要写个每秒自增的计数器。类组件的直觉是:“只需设置一次定时器,销毁一次”。这里有个例子。我们本能地把代码翻译成 useEffect 时加上了 []:“我只想运行一次嘛”。
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, []);
return <h1>{count}</h1>;
}但这个例子只会加一次。哎呀。
如果你的思维模型是“依赖数组让我决定何时重新触发 effect”,这个例子可能会让你怀疑人生。你想只触发一次,因为是定时器——那为什么会出问题?
其实很合理,因为依赖数组是我们给 React 的提示,告诉它 effect 用到了哪些组件作用域里的值。它用到了 count,但我们用 [] 骗它没用。迟早会出问题!
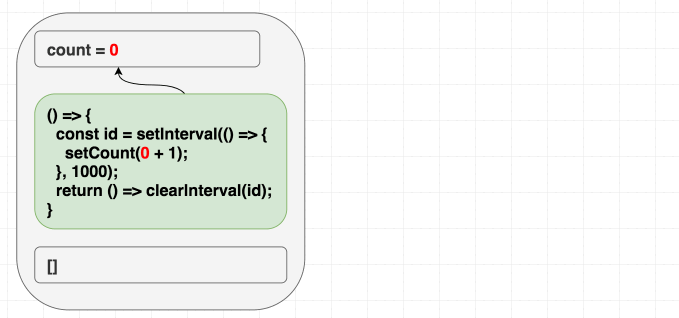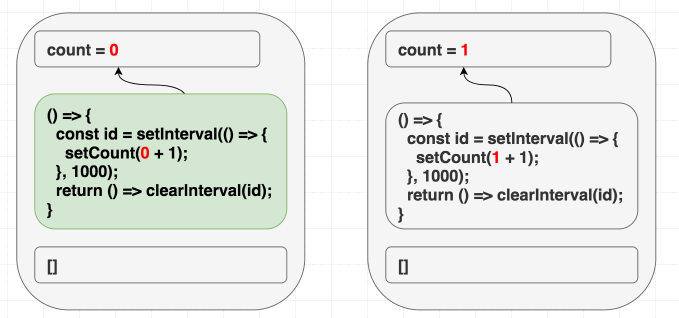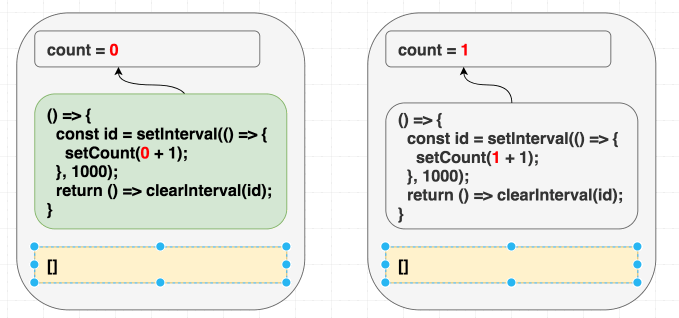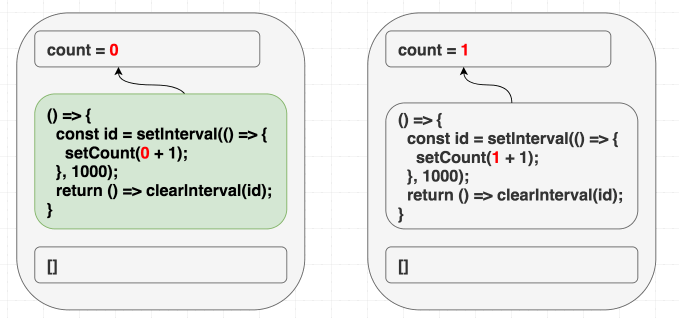
第一次渲染时,count 是 0。所以第一次 effect 里的 setCount(count + 1) 就是 setCount(0 + 1)。因为我们用 [],effect 永远不会重新运行,每秒都只会调用 setCount(1):
// 第一次渲染,state 是 0
function Counter() {
// ...
useEffect(
// 第一次渲染的 effect
() => {
const id = setInterval(() => {
setCount(0 + 1); // 总是 setCount(1)
}, 1000);
return () => clearInterval(id);
},
[] // 永远不重新运行
);
// ...
}
// 后续每次渲染,state 是 1
function Counter() {
// ...
useEffect(
// 这个 effect 永远被忽略,因为
// 我们用空依赖骗了 React。
() => {
const id = setInterval(() => {
setCount(1 + 1);
}, 1000);
return () => clearInterval(id);
},
[]
);
// ...
}我们骗了 React,说 effect 没用到组件里的值,其实用了!
effect 用到了 count——组件里的值(但在 effect 外部):
const count = // ...
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, []);所以写 [] 就会出 bug。React 会对比依赖,跳过 effect:
(依赖一样,跳过 effect。)
这种问题很难发现。所以我建议你养成习惯,永远如实写 effect 依赖。我们有个lint 规则可以全团队强制。
两种诚实写依赖的方法
有两种策略可以诚实地写依赖。一般先用第一种,不行再用第二种。
第一种策略是修正依赖数组,把 effect 用到的所有组件内的值都写进去。 比如把 count 加进去:
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, [count]);这样依赖数组就对了。也许不是最优,但这是第一步。现在 count 变了就会重新运行 effect,每次定时器用的都是那次渲染的 count:
// 第一次渲染,state 是 0
function Counter() {
// ...
useEffect(
// 第一次渲染的 effect
() => {
const id = setInterval(() => {
setCount(0 + 1); // setCount(count + 1)
}, 1000);
return () => clearInterval(id);
},
[0] // [count]
);
// ...
}
// 第二次渲染,state 是 1
function Counter() {
// ...
useEffect(
// 第二次渲染的 effect
() => {
const id = setInterval(() => {
setCount(1 + 1); // setCount(count + 1)
}, 1000);
return () => clearInterval(id);
},
[1] // [count]
);
// ...
}这样就修复了问题,但每次 count 变都会清除并重建定时器。可能不太理想:
(依赖变了,effect 重新运行。)
第二种策略是改写 effect,让它不再需要那些变化频繁的值。 不是骗 React,而是让 effect 本身不再依赖它们。
下面介绍几种常见的“消除依赖”技巧。
让 Effect 自给自足
我们想去掉 effect 里的 count 依赖。
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, [count]);要做到这一点,先问自己:我们用 count 干嘛? 其实只是用在 setCount。那其实我们根本不需要 count。当要基于上一次 state 更新 state 时,可以用 setState 的函数式写法:
useEffect(() => {
const id = setInterval(() => {
setCount(c => c + 1);
}, 1000);
return () => clearInterval(id);
}, []);我把这种情况叫做“伪依赖”。是的,count 必须作为依赖,因为我们写了 setCount(count + 1)。但其实我们只是想把 count 变成 count + 1 再“交还”给 React。可 React 自己就知道当前 count。我们只需要告诉 React:把 state 加一就行了。
这正是 setCount(c => c + 1) 的作用。你可以把它当作“发送一个指令”告诉 React 如何改变 state。这种“函数式写法”在其它场景也有用,比如批量更新。
注意我们是真的消除了依赖,没有作弊。effect 已经不再读取作用域里的 counter:
(依赖一样,effect 跳过。)
你可以试试。
即使这个 effect 只运行一次,属于第一次渲染的定时器回调也能每次都发出 c => c + 1 的更新指令。它不需要知道当前的 counter,React 自己知道。
函数式更新与 Google Docs
还记得我们说 effect 的思维模型是同步吗?同步的一个特点是,你通常希望系统间的“消息”不要和它们的状态纠缠在一起。比如 Google Docs 编辑文档时,并不会把整个页面发给服务器,那太低效了。它只会发用户的操作。
虽然我们的场景不同,但思想类似。effect 里只传递最必要的信息给组件就好。 setCount(c => c + 1) 传递的信息比 setCount(count + 1) 少,因为它不“污染”当前 count,只表达了“递增”这个动作。React 的思维方式就是找最小状态。这里也是同理,只不过是针对更新。
表达意图(而不是结果)就像 Google Docs 解决协同编辑那样。虽然有点牵强,但函数式更新在 React 里作用类似。它保证了多方(事件处理、effect 订阅等)的更新能批量、可预测地应用。
不过,setCount(c => c + 1) 其实也有限。 它看起来怪怪的,功能也有限。比如有两个 state 变量互相关联,或者需要用 prop 计算下一个 state,就不行了。幸运的是,setCount(c => c + 1) 有个更强大的姐妹模式——useReducer。
将更新与动作解耦
我们把例子改成有两个 state:count 和 step。定时器每次按 step 增加:
function Counter() {
const [count, setCount] = useState(0);
const [step, setStep] = useState(1);
useEffect(() => {
const id = setInterval(() => {
setCount(c => c + step);
}, 1000);
return () => clearInterval(id);
}, [step]);
return (
<>
<h1>{count}</h1>
<input value={step} onChange={e => setStep(Number(e.target.value))} />
</>
);
}(Demo)
我们没有作弊。既然 effect 里用到了 step,就加进依赖。这样代码才能正确运行。
现在的行为是,改变 step 会重启定时器——因为它是依赖项。很多时候这正是你想要的!重新设置 effect 没什么不好,除非有特别需求。
但如果我们想让定时器不因 step 变化而重启呢?怎么去掉 step 依赖?
如果设置 state 依赖另一个 state,可以考虑用 useReducer 替代。
当你写 setSomething(something => ...) 时,就可以考虑用 reducer。reducer 让你把组件里“发生了什么”的表达和 state 如何响应解耦。
我们把 step 依赖换成 dispatch:
const [state, dispatch] = useReducer(reducer, initialState);
const { count, step } = state;
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' }); // 不再用 setCount(c => c + step)
}, 1000);
return () => clearInterval(id);
}, [dispatch]);(Demo)
你可能会问:“这样有啥好处?”答案是,React 保证 dispatch 在组件整个生命周期内恒定。所以上面例子永远不用重建定时器。
问题解决!
(dispatch、setState、useRef 的容器值可以不用写进依赖,因为 React 保证它们静态。但写也没坏处。)
effect 不再读取 state,而是 dispatch 一个动作,描述发生了什么。这样 effect 就和 step state 解耦了。effect 不关心怎么更新 state,只负责描述发生了什么。reducer 集中处理更新逻辑:
const initialState = {
count: 0,
step: 1,
};
function reducer(state, action) {
const { count, step } = state;
if (action.type === 'tick') {
return { count: count + step, step };
} else if (action.type === 'step') {
return { count, step: action.step };
} else {
throw new Error();
}
}(Demo)
为什么 useReducer 是 Hook 的“作弊模式”
我们已经看到,如何在 effect 需要基于上一次 state 或另一个 state 更新时消除依赖。但如果我们需要用props计算下一个 state 呢? 比如 <Counter step={1} />,这时总得把 props.step 写进依赖吧?
其实也可以不用!可以把reducer 本身写到组件里读取 props:
function Counter({ step }) {
const [count, dispatch] = useReducer(reducer, 0);
function reducer(state, action) {
if (action.type === 'tick') {
return state + step;
} else {
throw new Error();
}
}
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
return <h1>{count}</h1>;
}这种写法会禁用一些优化,所以别滥用,但确实可以在 reducer 里访问 props。(Demo)
即使这样,dispatch 依然保证稳定。 所以 effect 依赖里可以不写它,也不会导致 effect 重新运行。
你可能会问:这怎么可能?reducer 怎么能在 effect 里访问 props?其实当你 dispatch 时,React 只是记住了 action——但会在下次渲染时调用你的 reducer。那时最新的 props 就在作用域里了,你也不在 effect 里。
所以我觉得 useReducer 是 Hook 的“作弊模式”。它让我把更新逻辑和事件解耦,从而消除不必要的依赖,避免 effect 频繁运行。
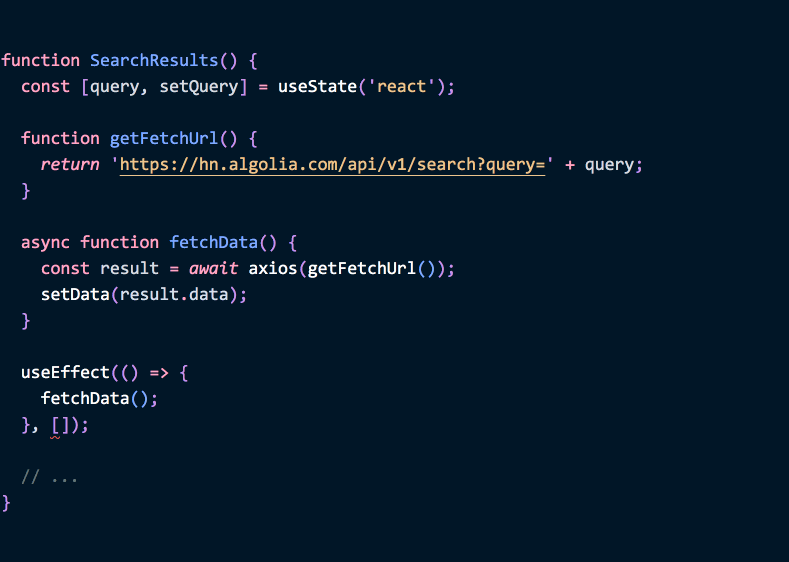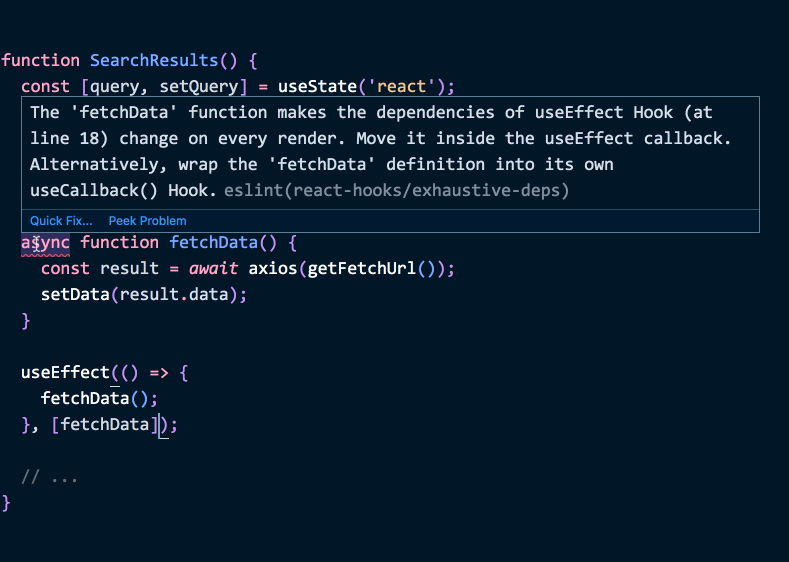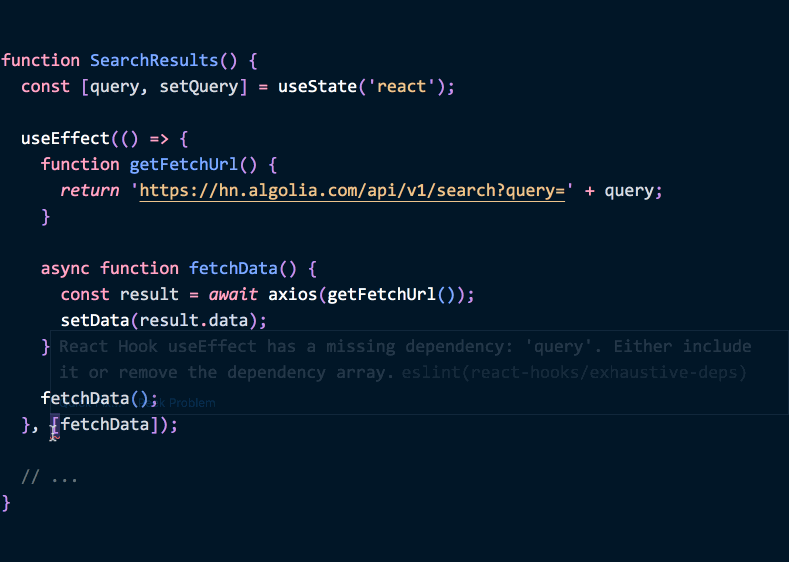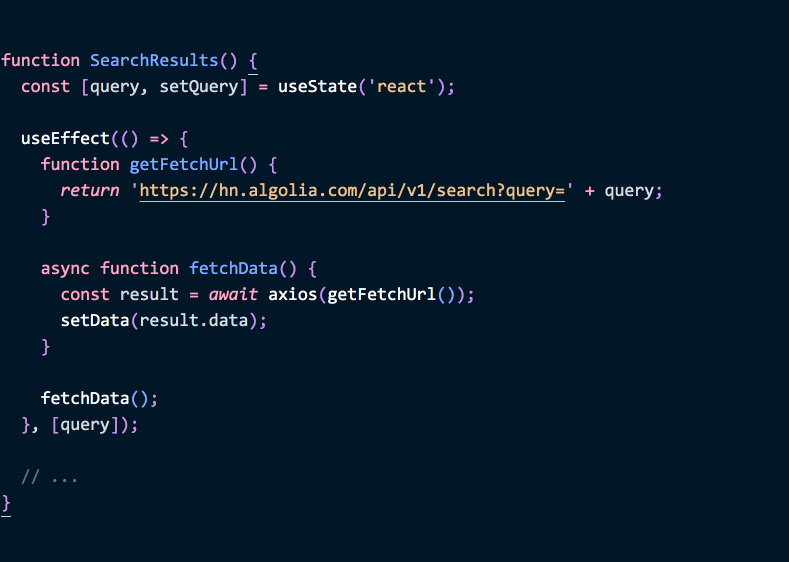
把函数写到 effect 里
常见误区是以为函数不该作为依赖。比如这样看起来没问题:
function SearchResults() {
const [data, setData] = useState({ hits: [] });
async function fetchData() {
const result = await axios(
'https://hn.algolia.com/api/v1/search?query=react',
);
setData(result.data);
}
useEffect(() => {
fetchData();
}, []); // 这样可以吗?
// ...(这个例子改编自 Robin Wieruch 的好文——推荐阅读!)
确实,这段代码能跑。但问题在于,简单地省略本地函数后,组件变大后很难判断是否处理了所有情况!
想象下代码拆成这样,每个函数都很长:
function SearchResults() {
// 假设这个函数很长
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=react';
}
// 假设这个函数也很长
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
useEffect(() => {
fetchData();
}, []);
// ...
}后来我们在某个函数里用到了 state 或 prop:
function SearchResults() {
const [query, setQuery] = useState('react');
// 假设这个函数也很长
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
// 假设这个函数也很长
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
useEffect(() => {
fetchData();
}, []);
// ...
}如果我们忘了更新 effect 的依赖(可能是通过别的函数间接调用),effect 就无法同步 props 和 state 的变化。这可不妙。
幸运的是,有个简单办法。如果某些函数只在 effect 里用,就直接写到 effect 里:
function SearchResults() {
// ...
useEffect(() => {
// 把函数搬进来!
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=react';
}
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
fetchData();
}, []); // ✅ 依赖没问题
// ...
}(Demo)
好处是什么?我们不用再考虑“传递依赖”了。依赖数组没有撒谎:effect 里确实没用到组件外部的东西。
如果以后 getFetchUrl 用了 query state,我们很容易发现是在 effect 里改的——于是要把 query 加进依赖:
function SearchResults() {
const [query, setQuery] = useState('react');
useEffect(() => {
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
fetchData();
}, [query]); // ✅ 依赖没问题
// ...
}(Demo)
加上这个依赖,不只是“安抚 React”。当 query 变了需要重新获取数据,这很合理。useEffect 的设计让你必须关注数据流的变化,并决定 effect 如何同步,而不是等用户遇到 bug。
有了 eslint-plugin-react-hooks 的 exhaustive-deps 规则,你可以在编辑器里实时分析 effect,提示哪些依赖漏了。也就是说,机器能帮你发现数据流没处理好的地方。
很赞吧。
但有些函数不能放进 effect 怎么办
有时你不想把函数搬进 effect。比如同一个函数被多个 effect 调用,不想复制粘贴。或者它是个 prop。
这种情况能不能不写函数依赖?我觉得不行。effect 不该对依赖撒谎。 通常有更好的办法。常见误区是“函数永远不会变”。但我们已经学过,组件里的函数每次渲染都会变!
这本身就是个问题。 比如两个 effect 都调用 getFetchUrl:
function SearchResults() {
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
useEffect(() => {
const url = getFetchUrl('react');
// ... 获取数据 ...
}, []); // 🔴 缺少依赖 getFetchUrl
useEffect(() => {
const url = getFetchUrl('redux');
// ... 获取数据 ...
}, []); // 🔴 缺少依赖 getFetchUrl
// ...
}这时你可能不想把 getFetchUrl 搬进 effect,因为要复用。
但如果你“诚实”写依赖,就会遇到问题。因为每次渲染 getFetchUrl 都变,依赖数组没意义:
function SearchResults() {
// 🔴 每次渲染都触发所有 effect
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
useEffect(() => {
const url = getFetchUrl('react');
// ... 获取数据 ...
}, [getFetchUrl]); // 🚧 依赖对了但每次都变
useEffect(() => {
const url = getFetchUrl('redux');
// ... 获取数据 ...
}, [getFetchUrl]); // 🚧 依赖对了但每次都变
// ...
}你可能会想干脆不写 getFetchUrl。但这样很难发现数据流变了需要处理,容易出 bug,比如前面说的定时器问题。
其实有两个更简单的办法。
首先,如果函数没用到组件作用域的值,可以提升到组件外部,effect 里随便用:
// ✅ 不受数据流影响
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
function SearchResults() {
useEffect(() => {
const url = getFetchUrl('react');
// ... 获取数据 ...
}, []); // ✅ 依赖没问题
useEffect(() => {
const url = getFetchUrl('redux');
// ... 获取数据 ...
}, []); // ✅ 依赖没问题
// ...
}不用写进依赖,因为它不在渲染作用域里,不会受数据流影响,也不会意外用到 props 或 state。
或者用 useCallback Hook 包裹:
function SearchResults() {
// ✅ 只有依赖变才变
const getFetchUrl = useCallback((query) => {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, []); // ✅ 依赖没问题
useEffect(() => {
const url = getFetchUrl('react');
// ... 获取数据 ...
}, [getFetchUrl]); // ✅ 依赖没问题
useEffect(() => {
const url = getFetchUrl('redux');
// ... 获取数据 ...
}, [getFetchUrl]); // ✅ 依赖没问题
// ...
}useCallback 就像多加了一层依赖检查。不是避免函数依赖,而是让函数本身只在必要时变化。
来看这个办法的好处。前面的例子是两个固定 query。现在我们加个输入框,可以搜索任意 query,于是 getFetchUrl 不再接收参数,而是直接读取本地 state。
这时你会发现漏写了 query 依赖:
function SearchResults() {
const [query, setQuery] = useState('react');
const getFetchUrl = useCallback(() => { // 没有 query 参数
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, []); // 🔴 缺少依赖 query
// ...
}只要把 useCallback 的依赖补上,所有用到 getFetchUrl 的 effect 就会在 query 变时重新运行:
function SearchResults() {
const [query, setQuery] = useState('react');
// ✅ 只有 query 变才变
const getFetchUrl = useCallback(() => {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, [query]); // ✅ 依赖没问题
useEffect(() => {
const url = getFetchUrl();
// ... 获取数据 ...
}, [getFetchUrl]); // ✅ 依赖没问题
// ...
}有了 useCallback,只要 query 没变,getFetchUrl 也不会变,effect 就不会重新运行。只有 query 变了,getFetchUrl 也变,才会重新获取数据。这很像 Excel 表格,某个单元格变了,相关单元格自动重新计算。
这就是拥抱数据流和同步思维的结果。同样的办法也适用于父组件传下来的函数 prop:
function Parent() {
const [query, setQuery] = useState('react');
// ✅ 只有 query 变才变
const fetchData = useCallback(() => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + query;
// ... 获取数据并返回 ...
}, [query]); // ✅ 依赖没问题
return <Child fetchData={fetchData} />
}
function Child({ fetchData }) {
let [data, setData] = useState(null);
useEffect(() => {
fetchData().then(setData);
}, [fetchData]); // ✅ 依赖没问题
// ...
}只要 fetchData 只在 Parent 的 query 变时才变,Child 就不会重复获取数据,只有真正需要时才会。
函数是数据流的一部分吗?
有趣的是,这种模式在类组件里是做不到的,充分体现了 effect 和生命周期范式的区别。来看翻译版:
class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query;
// ... 获取数据 ...
};
render() {
return <Child fetchData={this.fetchData} />;
}
}
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
render() {
// ...
}
}你可能会说:“Dan,大家都知道 useEffect 就是 componentDidMount 加 componentDidUpdate,你别再说了!”但即使用 componentDidUpdate 也不行:
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) {
// 🔴 这个条件永远不会成立
if (this.props.fetchData !== prevProps.fetchData) {
this.props.fetchData();
}
}
render() {
// ...
}
}因为 fetchData 是类方法!(其实是类属性,但没区别。)它不会因为 state 变而变。所以 this.props.fetchData 总等于 prevProps.fetchData,永远不会重新获取。那干脆去掉条件?
componentDidUpdate(prevProps) {
this.props.fetchData();
}这样每次渲染都会获取。(上面有动画时更容易发现。)那要不要 bind 一下?
render() {
return <Child fetchData={this.fetchData.bind(this, this.state.query)} />;
}但这样 this.props.fetchData !== prevProps.fetchData 总是 true,即使 query 没变!所以每次都重新获取。
类组件唯一的解决办法,就是把 query 也传给 Child。Child 实际上不用 query,但可以用它判断是否重新获取:
class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query;
// ... 获取数据 ...
};
render() {
return <Child fetchData={this.fetchData} query={this.state.query} />;
}
}
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) {
if (this.props.query !== prevProps.query) {
this.props.fetchData();
}
}
render() {
// ...
}
}多年来我用类组件时,早已习惯了传递无用的 prop,破坏了父组件的封装,直到最近才明白为什么。
在类组件里,函数 prop 本身不是数据流的一部分。 方法闭包了可变的 this,无法靠 identity 判断是否变了。所以即使只想传递函数,也得带上一堆其它数据,方便“对比”。我们无法知道父组件传下来的 this.props.fetchData 是否依赖 state,以及 state 是否刚变。
有了 useCallback,函数就能完全参与数据流。 如果输入变了,函数就变,否则不变。得益于 useCallback 的粒度,prop 变化能自动传递下去。
同理,useMemo 也可以用于复杂对象:
function ColorPicker() {
// 只有 color 变才会破坏 Child 的浅比较
const [color, setColor] = useState('pink');
const style = useMemo(() => ({ color }), [color]);
return <Child style={style} />;
}但我想强调,处处用 useCallback 很繁琐。 它是个好用的逃生舱,适合函数既要传下去又要在子 effect 里用,或者你想避免破坏子组件的 memo。但 Hook 更适合避免传递回调。
上面这些例子,我更希望 fetchData 直接写在 effect 里(也可以抽成自定义 Hook),或者直接 import。我要让 effect 简单,回调反而让它复杂。(“如果 props.onComplete 在请求过程中变了怎么办?”)你可以模拟类组件行为,但 race condition 还是没法解决。
说到竞态条件
类组件里经典的数据获取例子:
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}你可能知道,这段代码有 bug。它没处理更新。于是网上常见的第二版是:
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
componentDidUpdate(prevProps) {
if (prevProps.id !== this.props.id) {
this.fetchData(this.props.id);
}
}
async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}这样确实好点!但还是有 bug。因为请求可能乱序。如果我先请求 {id: 10},再切到 {id: 20},但 {id: 20} 的请求先返回,之前的请求后来返回就会把 state 覆盖掉。
这叫竞态条件,是 async/await(假设结果会等)和自上而下数据流(props 或 state 可能中途变)混用的典型问题。
effect 并不会神奇地解决这个问题,虽然你直接传 async 函数给 effect 时会有警告(我们还要改进这个警告)。
如果 async 方法支持取消,那最好!可以在 cleanup 里取消请求。
或者最简单的办法是用布尔值跟踪:
function Article({ id }) {
const [article, setArticle] = useState(null);
useEffect(() => {
let didCancel = false;
async function fetchData() {
const article = await API.fetchArticle(id);
if (!didCancel) {
setArticle(article);
}
}
fetchData();
return () => {
didCancel = true;
};
}, [id]);
// ...
}这篇文章有更多关于错误处理、加载状态以及如何抽成自定义 Hook 的内容。想深入了解用 Hook 获取数据,推荐一读。
提高标准
用类生命周期思维时,副作用和渲染输出是分离的。UI 渲染由 props 和 state 驱动,保证一致,但副作用不是。这是常见 bug 源头。
用 useEffect 思维,副作用默认就是同步的。副作用变成 React 数据流的一部分。每个 useEffect,只要写对了,组件就能更好地处理边界情况。
但写对的门槛更高。这可能让人烦躁。写好同步代码本来就比写一次性副作用难。
如果 useEffect 是你最常用的工具,这可能会让人担心。但它其实是底层构件。现在 Hook 刚出来,大家都用底层的,尤其是教程。但实际开发中,社区会逐渐转向更高级的 Hook。
我看到很多应用都写了自己的 useFetch(封装鉴权等逻辑)或 useTheme(用主题 context)。有了这些工具,你其实很少直接用 useEffect。但它带来的健壮性会让所有基于它的 Hook 受益。
目前 useEffect 最常用场景是获取数据。但数据获取其实不太像同步问题。尤其是依赖常常写 [],那我们到底在同步什么?
长远来看,Suspense for Data Fetching 会让第三方库能优雅地告诉 React 等待异步资源(代码、数据、图片等)。
随着 Suspense 覆盖更多数据获取场景,我预计 useEffect 会逐渐淡出,成为只有需要同步 props 和 state 到副作用时的高级工具。和数据获取不同,effect 天生适合同步。但在此之前,像这里这样的自定义 Hook 是复用数据获取逻辑的好办法。
总结
现在你已经知道了我关于 effect 的几乎所有知识,可以回头看看开头的 TLDR。你觉得有道理吗?我有遗漏吗?(我还没写完呢!)
欢迎在 Twitter 上和我交流!感谢阅读。
Pay what you like